
Soziale Gerechtigkeit beim Lernen mit KI
Wie künstliche Intelligenz aufgestellt werden kann, dass sie für alle Schüler*innen wirkt
von Adrian Grimm & Anneke Steegh
Künstliche Intelligenz (KI) wird zunehmend im Physikunterricht genutzt – und deren Einsatz ist auch lernwirksam. Lernwirksam für alle? Inwiefern Bias – also systematische Verzerrungen – bei der Nutzung von KI im Physikunterricht zum Tragen kommen und die naturwissenschaftliche Identität von Schüler*innen beeinträchtigen, untersucht eine Forschungsgruppe am IPN.

Die Entwicklung einer naturwissenschaftlichen Identität, also die positive Selbsteinschätzung hinsichtlich der Aussage „Naturwissenschaftler*in – das bin ich“, hängt maßgeblich von Anerkennung ab. Dabei spielt vor allem die Anerkennung durch Personen eine Rolle, die als fachlich kompetent wahrgenommen werden – bei Schüler*innen etwa ihre Physiklehrkräfte.
Im Physikunterricht wird KI unter anderem dazu verwendet, Antworten von Schüler*innen automatisiert auszuwerten. Diese Auswertungen führen oft direkt zu Rückmeldungen an die Schüler*innen oder dienen den Lehrkräften als Grundlage für Feedback, das entscheidend zur Anerkennung beiträgt.
Deswegen ist Bias bei KI identitätsrelevant
Was ist ein Bias? Von Bias in KI sprechen wir, wenn KI beispielsweise systematisch besser für Schüler funktioniert als für Schülerinnen. Dies kann passieren, weil die KI mit historischen Daten trainiert wird. Wenn diese Daten bereits einen Bias enthalten, übernimmt die KI diesen, sodass sie am Ende ebenfalls voreingenommene Ergebnisse liefert.
Wenn KI für bestimmte Gruppen wie weibliche oder nicht-binäre Schüler*innen weniger zuverlässig funktioniert, kann das zu unbegründeten negativen Rückmeldungen führen. Die betroffenen Schüler*innen haben dann weniger Gelegenheit, eine starke naturwissenschaftliche Identität zu entwickeln. Dies wiederum kann die Ungleichheiten verstärken, die heute bereits sichtbar sind: Entlang von Geschlechtsidentität zeigt sich ein großes Gefälle, wenn es um Berufe geht, in denen Physik eine zentrale Rolle spielt, beispielsweise Elektrotechniker*in oder Ingenieur*in.
Auf dem Weg zu einer gerechten KI
Wie das Training von KI funktioniert, hat Andreas Mühling in seinem Beitrag im IPN Journal Nr. 11 bildhaft und für Einsteiger*innen geeignet erläutert. Für Praktiker*innen im Bereich der KI existieren viele Codes of Conduct, die Diskriminierung verbieten. Gleichzeitig belegen zahlreiche Forschungsarbeiten, dass Bias in KI kein Einzelfall sind, sondern systematisch vorkommen, und dass es eine große Lücke gibt zwischen Diskriminierungsverbot auf dem Papier und dem, was in der KI-Praxis geschieht. In einer Fallstudie konnten wir für ein Beispiel im Physikunterricht aufzeigen, warum es diese Lücke gibt: Vorgaben zum Diskriminierungsverbot sind häufig nicht ausreichend spezifiziert. Deswegen müssen wir uns als KI-Community folgende Fragen ganz bewusst stellen: Gegen welche konkreten Bias braucht es präventive Maßnahmen? Spezifischer für den Physikunterricht: Welche Bias sind im Physikunterricht besonders relevant und wie können wir ihnen effektiv und effizient mit politischer Regulierung begegnen?
Ein Spannungsfeld: Politische Vorgaben
Ausgangspunkt ist die Frage: Beantworten Schüler*innen je nach Geschlechtsidentität, Migrationsgeschichte und Behinderung Physikaufgaben unterschiedlich? Es könnte sein, dass Schüler*innen der siebten und achten Klasse Aufgaben zu Energie genau gleich beantworten, wir also keine Unterschiede finden. In diesem Fall wäre es eine Überregulierung, wenn politisch vorgeschrieben wird, wie Trainingsdaten in Bezug auf Geschlechtsidentität zusammengesetzt sein müssen und damit eine unnötige bürokratische Hürde. Oder gibt es einen Unterschied in den Antworten? Dann kann Regulierung notwendig sein, um keine Schüler*innen mit KI zu diskriminieren. Unsere bisher unveröffentlichten ersten Ergebnisse deuten darauf hin, dass es Bias in KI für Physikunterricht gibt, wenn nicht aktiv gegengesteuert wird. Durch unsere Forschung kann identifiziert werden, an welchen Stellschrauben diesem Bias besonders effektiv und effizient entgegengewirkt werden kann.
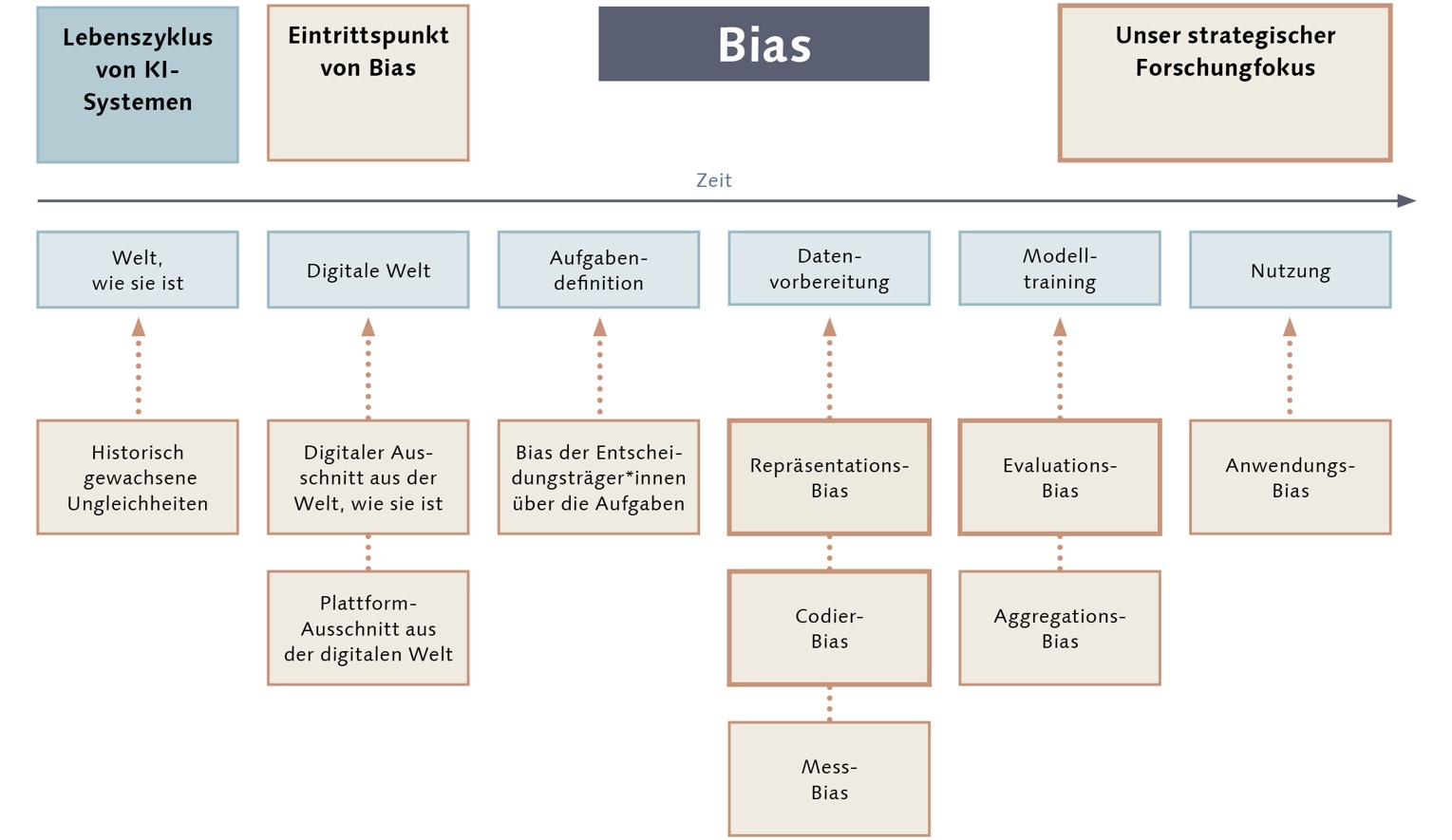
So kommt Bias in KI
Im Lebenszyklus von KI-Systemen gibt es mehrere Phasen, in denen Bias entstehen kann. Wir konzentrieren uns auf die Phasen der Datenvorbereitung und des Modelltrainings, da sie für den Physikunterricht am ehesten regulatorisch zu beeinflussen sind und vielversprechendes Potenzial beinhalten.
Repräsentations-Bias
In der Phase der Datenvorbereitung und des Modelltrainings kann eine Verzerrung auftreten, wenn die verwendeten Daten nicht repräsentativ für die spätere Anwendung sind. Dies wird als Repräsentations-Bias bezeichnet. Ein Beispiel dafür ist, wenn ein KI-System nur mit Daten von Gymnasien trainiert wird, aber später an anderen Schultypen wie Gemeinschaftsschulen eingesetzt werden soll. Die KI könnte dann an diesen anderen Schultypen schlechter funktionieren, weil die Unterschiede zwischen den Schulen in den Trainingsdaten nicht berücksichtigt wurden.
Codier-Bias
Der Codier-Bias beschreibt, dass Schüler*innen-Antworten von Menschen ausgewertet werden und dass dabei einige Schüler*innen systematisch schlechter bewertet werden als sie sind. Ein Beispiel: Antworten von Schülerinnen werden von einer codierenden Person systematisch schlechter bewertet als die Antworten von Schülern, was uns allen wegen des Einflusses gesellschaftlicher Vorurteile unabsichtlich passieren kann. Wenn dann mit dieser Auswertung eine KI trainiert wird, hat diese KI einen Bias und bewertet ebenfalls systematisch die Antworten von Schülerinnen schlechter.
Evaluations-Bias
Außerdem schauen wir auf den Evaluations-Bias, bei dem die Verzerrung dadurch entsteht, dass eine Prüfmethode so angelegt ist, dass bestehende Diskriminierungen nicht aufgedeckt werden. Wird z. B. eine KI nur dahingehend überprüft, ob eine Klasse im Durchschnitt mehr lernt als ohne KI, so sagt dies nichts über den Bias aus. Es könnte sein, dass Schüler in dieser Klasse im Durchschnitt viel mehr mit KI lernen als die Schülerinnen. Notwendig wäre dann eine separate Evaluation der Gruppen von Schüler*innen, basierend auf Gender, zusätzlich zu einer Gesamtevaluation.
Strategien zur Minimierung von Bias: Unsere Forschungsansätze
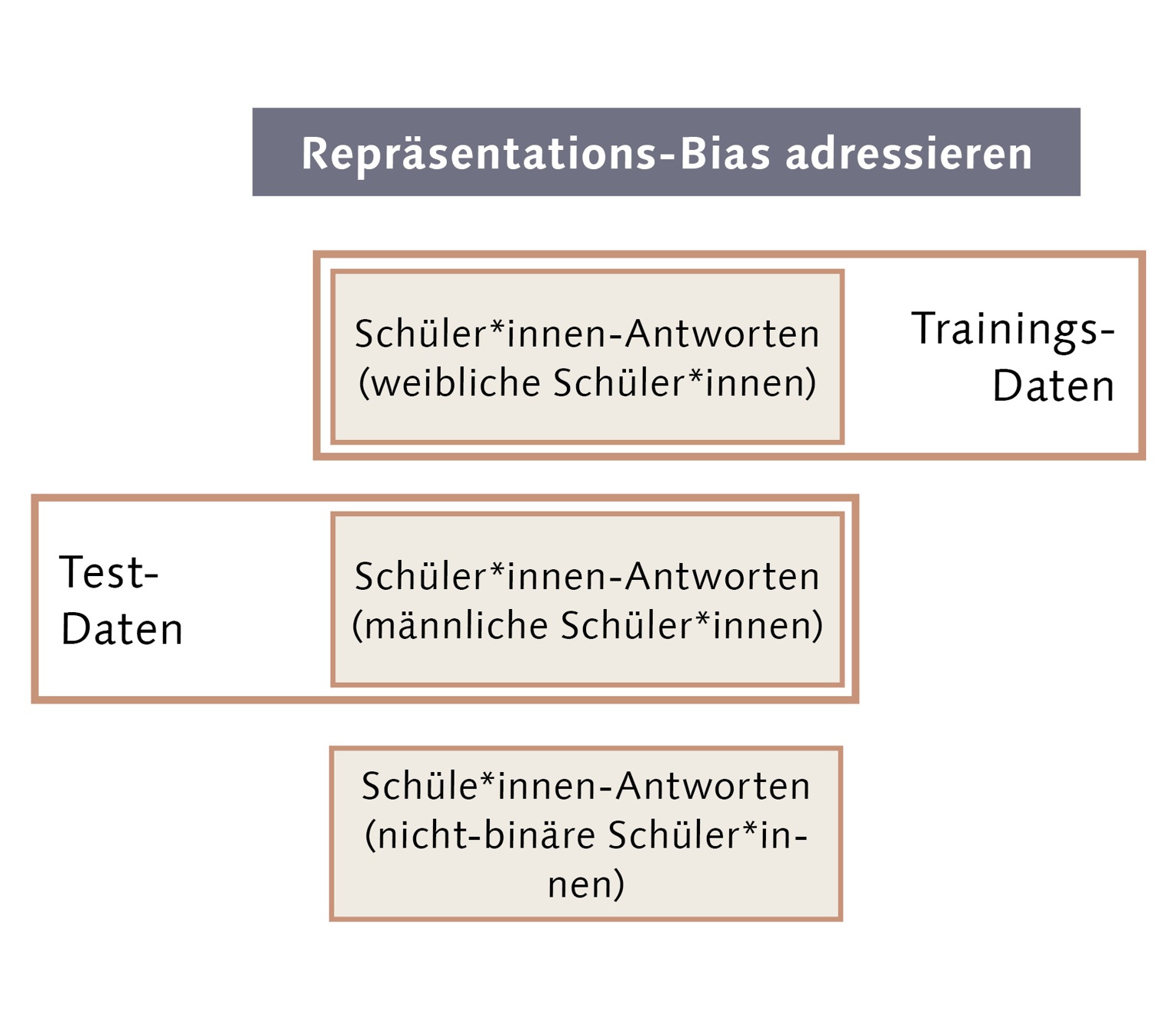
Wir sind im Moment dabei zu prüfen, ob es einen Unterschied macht, mit welchen Daten eine KI trainiert wird. Dafür trainieren wir die KI nur mit Daten von Schülerinnen, dann mit 10% Daten von Schülern und 90% Daten von Schülerinnen, darauffolgend mit 20% zu 80%, bis wir sie schließlich mit 100% Daten von Schülern trainieren. Abschließend evaluieren wir, ob – abhängig von den Trainingsdaten – die KI für Schülerinnen schlechter funktioniert als für Schüler. Unsere ersten Ergebnisse deuten darauf hin, dass die Zusammensetzung der Trainingsdaten einen Effekt hat, aber nicht allein für Bias in KI verantwortlich ist.
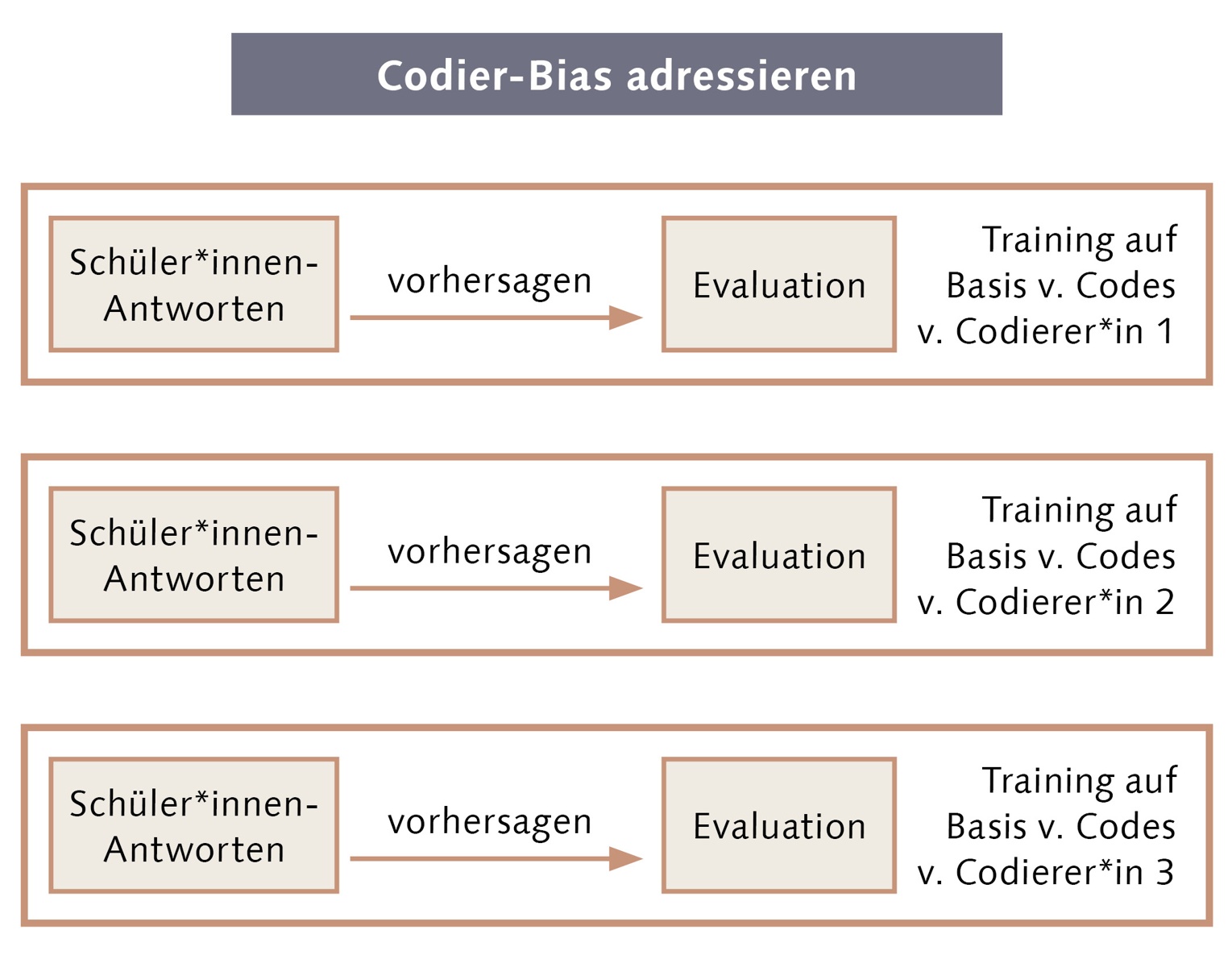
Außerdem widmen wir uns der Frage, wie ein Codier-Bias adressiert werden kann. Dafür lassen wir die gleichen Antworten von Schüler*innen durch mehrere Codierer*innen auswerten. Anschließend schauen wir, ob die KI – in Abhängigkeit davon, wer die Daten codiert hat – unterschiedlich gut für Schülerinnen und Schüler funktioniert. Wenn es einen Unterschied macht, scheint ein Codier-Bias vorzuliegen. Diesem Codier-Bias muss dann schon vor dem eigentlichen Training der KI entgegengewirkt werden. Hier befinden wir uns noch in der Auswertung der ersten Datensätze.
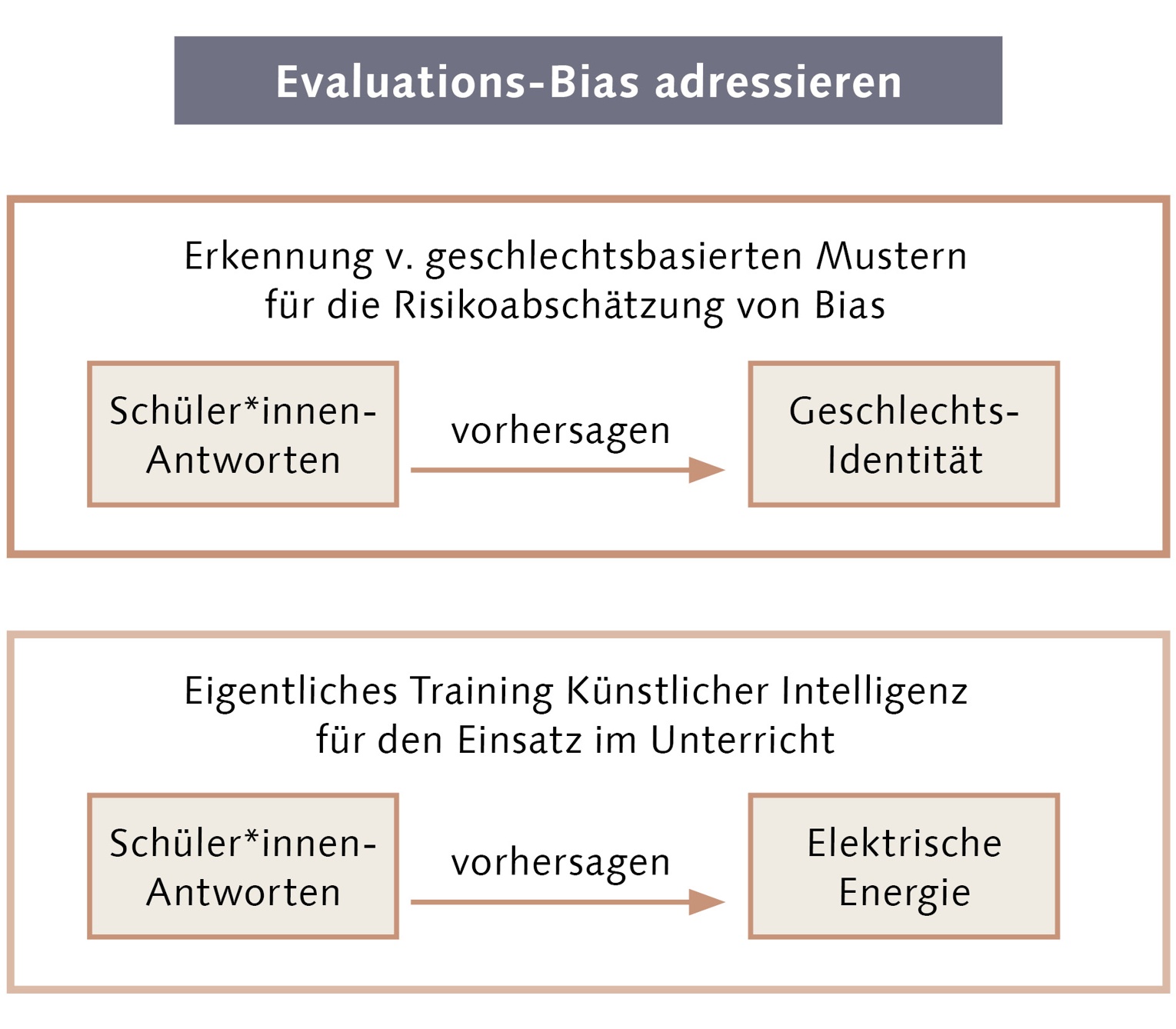
Zuletzt widmen wir uns noch der Frage, wie ein Repräsentations-Bias adressiert werden kann. Hierfür versuchen wir zunächst, mit den Antworten der Schüler*innen die Geschlechtsidentität von Schüler*innen vorherzusagen. Wenn das funktioniert, gibt es offensichtlich geschlechtsbasierte Muster in den Antworten der Schüler*innen. Und je besser das funktioniert, umso stärker sind die Muster. Eine KI lernt Muster aus Trainingsdaten. Deswegen gilt zunächst ohne Berücksichtigung weiterer Aspekte: Je größer die geschlechtsbasierten Muster in den Schüler*innen-Antworten sind, umso größer ist die Gefahr, dass die KI diese Muster als Abkürzung verwenden wird. Dies wäre problematisch, weil es eine Diskriminierung darstellt und eben keine an Qualitätskriterien orientierte Auswertung. Eine solche Risikoeinschätzung kann dazu dienen, Auflagen zur Evaluation von KI höher oder niedriger auszugestalten. Unsere ersten Ergebnisse deuten darauf hin, dass eine Risikoeinschätzung funktioniert. Also: Je besser eine KI die Geschlechtsidentität von Schüler*innen vorhersagen kann, umso größer ist auch ihr geschlechtsbasierter Bias.
Fazit: Gerechte KI erfordert politische Regulierung
KI hält zunehmend Einzug in den Physikunterricht und das ist richtig, weil das Lernen dadurch unterstützt wird. Wir arbeiten aber auch daran, dass das Lernen für alle Schüler*innen gleichermaßen unterstützt wird. Damit soll die ohnehin schon bestehende Unterrepräsentation von beispielsweise Schülerinnen nicht noch weiter verstärkt werden. KI im Physikunterricht ist nicht automatisch ohne Bias, im Gegenteil: Es erfordert aktive Arbeit, mit KI zu arbeiten, die keinen Bias hat.

Über die Autor*innen:

Adrian Grimm (er) ist wissenschaftlicher Mitarbeiter der Didaktik der Physik am IPN. In seiner Forschung widmet er sich insbesondere der Frage, wie naturwissenschaftlicher Unterricht so gestaltet werden kann, dass alle Schüler*innen eingeladen werden, sodass historisch gewachsene Ungleichheiten entlang von Diversitätsdimensionen aktiv abgebaut werden. grimm@leibniz-ipn.de
Mastodon: @AdrianGrimm@digitalcourage.social

Dr. Anneke Steegh ist Postdoktorandin am IPN in den Abteilungen Didaktik der Chemie. Sie forscht zu MINT-Identität und marginalisierten Identitäten in der MINT-Bildung. steegh@leibniz-ipn.de
Weiterführende Literatur:
Grimm, A., Steegh, A., Çolakoğlu, J., Kubsch, M., & Neumann, K. (2023). Positioning responsible learning analytics in the context of STEM identities of under-served students. Frontiers in Education, 7. https://doi.org/10.3389/feduc.2022.1082748
Grimm, A., Steegh, A., Kubsch, M., & Neumann, K. (2023). Learning Analytics in Physics Education: Equity- Focused Decision-Making Lacks Guidance! Journal of Learning Analytics, 10(1), 71–84. https://doi.org/10.18608/jla.2023.7793
Mühling, A. (2024). Die Lernumgebungen des KI-Labors. IPN Journal, 2024(11), 18–20.





